모아온의 아티클 조회 API의 성능 테스트를 하다가 이상한 현상을 발견했다. 같은 API를 반복 실행할 때 첫 번째만 유독 응답 속도가 느렸다. 캐시와 관련된 것이겠지 단순 추측해 볼 수는 있었지만, 정확히 어떤 매커니즘인지 궁금해졌다.
이 글에서는 해당 현상의 정체를 파헤쳐본다.
이 글에서 다루는 내용
- InnoDB 버퍼 풀의 구조와 역할
- LRU 캐시 알고리즘
대상 독자
- MySQL 사용자, 백엔드 개발자
- 메모리 계층 구조와 캐싱에 대한 기본 이해가 있는 사람
1. 문제 상황
1.1 API 성능 테스트 중 속도 차이 발견
성능 테스트를 할 때, 최초 조회가 유독 시간이 많이 걸리는 현상을 흔히 발견할 수 있다. 모아온의 아티클 조회 API 성능 개선을 위해 테스트 데이터를 넣고 실험을 진행했을 때, 해당 실험의 첫 시도와 다음 시도의 속도가 차이가 매우 컸다. API마다 그 차이는 제각각이었지만 명확히 보이는 현상이었다. 아래의 가장 간단한 예시의 경우 3배까지 속도 차이가 벌어졌다.
실험 환경
- 데이터: 아티클 100만 건
- API: 100개 조회 (정렬, 페이징)
- 환경: 로컬 (MySQL 8.4)
- 측정: Postman으로 5회 반복
실험 대상 API
GET /articles?sort=createdAt&limit=100실험 결과

1.2 궁금증
맨 처음 이런 현상을 발견했을 때 명확한 이유를 알지 못했다. “캐시와 관련된 문제 아닐까” 하는 추측만 있었다.
그래서 성능 측정 결과를 기록할 때, 최초 기록을 포함해 5~10회 정도 테스트 후 평균 값을 기록했다.
자연스레 다음과 같은 궁금증이 생겼다:
- 최초 조회만 유독 시간이 오래 걸리는 정확한 이유는 무엇일까❓
- 이것은 문제 상황일까, 아니면 정상 동작일까❓
- 최초 조회 결과도 성능 측정에 포함시켜야 할까❓
- 실제 서비스에서 첫 사용자가 느린 경험을 하는 건 괜찮을까❓
1.3 원인 추적
이 현상에 대한 해답은 간단하게 도출해 낼 수 있다. 바로 디스크와 메모리의 속도 차이에서 비롯된 문제다.
DBMS는 영속성을 위해 데이터를 디스크에 저장한다. 따라서 최초 조회를 할 때는 데이터를 디스크로부터 읽어오기 때문에 시간이 오래 걸릴 수 밖에 없다. 이 과정에서 데이터를 메모리에 올렸다가 읽어드릴 것이고, 두 번째 조회 부터는 디스크를 거치지 않고 메모리 조회를 바로 할 수 있다.
Disk vs Memory

위 사진은 CS 공부를 할 때 흔하게 볼 수 있는 Memory Hierarchy 피라미드이다. 디스크와 메모리의 속도 차이는 응답 속도에 큰 영향을 미칠 수 밖에 없다.
- RAM: ~100ns
- SSD: ~100μs → RAM보다 1,000배 느림
- HDD: ~10ms → RAM보다 100,000배 느림
MySQL의 해결책: InnoDB Buffer Pool
모든 데이터를 빠른 메모리에 올려두고 사용하면 좋겠지만, 메모리의 크기는 제한적이다. 따라서 자주 쓰는 데이터만 선택적으로 메모리에 오래 머무르게 하는 캐싱 전략이 필요하다.
MySQL에서 이 역할을 담당하는 것이 바로 InnoDB 엔진의 Buffer Pool 이다.
2. 파고들기
우리의 궁금증에 대한 키를 찾았다. 사실 이정도로만 설명해도 궁금증에 대한 충분한 답이 될 수 있다.
하지만 "그래서 어떻게 Buffer Pool이 작동하는건데?"에 대한 궁금증이 해소되지 않았다. 좀 더 파고 들어가보자!
2.1 MySQL 엔진 아키텍처
우선 InnoDB가 하는 역할에 대해 알아보자.
MySQL 서버의 전체 구조
MySQL 클라이언트(애플리케이션 프로그램 등)이 SQL을 실행하면, MySQL 서버는 해당 쿼리를 해석해서 필요한 데이터를 읽어온 후 반환한다. MySQL 서버는 크게 MySQL 엔진과 스토리지 엔진으로 구분할 수 있다.
- MySQL 엔진: 요청된 SQL 문장을 분석하거나 최적화하는 등 DBMS의 두뇌에 해당한다.
- 스토리지 엔진: 실제 데이터를 저장하거나 읽어오는 등 DBMS의 손발에 해당한다. MyISAM, InnoDB 등이 있다.

InnoDB 스토리지 엔진 아키텍처
InnoDB 버퍼 풀은 InnoDB 스토리지 엔진에서 가장 핵심적인 부분으로, 디스크 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간이다. 쓰기 작업을 지연시켜 일괄 작업으로 처리할 수 있게 해주는 버퍼 역할도 같이 한다.

버퍼 풀의 역할
버퍼 풀의 주요 역할은 두가지가 있다. 메모리를 관리해 읽기 성능과 쓰기 성능을 개선한다. 이 중 우리는 버퍼 풀이 읽기 성능을 향상시키기 위해 어떤 캐싱 전략을 사용하는지 알아볼 것이다.
- 읽기 성능 향상
- 자주 사용하는 데이터를 메모리에 캐싱
- 디스크 I/O 최소화
- 쓰기 성능 향상
- 변경사항을 버퍼에 모았다가 일괄 처리
- 디스크 쓰기 횟수 감소
버퍼 풀의 구조
버퍼 풀은 데이터를 "페이지" 단위로 관리한다.
- 페이지 크기: 기본 16KB (innodb_page_size)
- 데이터, 인덱스 모두 페이지 단위로 저장
버퍼풀은 페이지를 3가지 종류의 리스트를 이용해 관리한다.
- Free 리스트: 비어있는 페이지 목록
- LRU 리스트: 캐시 관리를 위한 핵심
- Flush 리스트: 변경된 페이지(Dirty Page) 관리
2.2 캐시 관리: LRU 알고리즘
문제상황: 제한된 메모리
앞서 살펴본 것처럼 버퍼 풀은 자주 접근되는 데이터를 메모리에 캐싱한다. 하지만 메모리는 무한하지 않다. MySQL의 기본 버퍼 풀 크기는 128MB에 불과하다. 페이지 크기가 16KB라고 했을 때, 최대 8,192개의 페이지만 캐싱할 수 있다는 뜻이다.
그렇다면 버퍼 풀이 가득 찼을 때, 어떤 페이지를 유지하고 어떤 페이지를 제거해야 할까?
InnoDB는 이 문제를 LRU(Least Recently Used) 알고리즘의 변형 버전으로 해결한다.
Least Recently Used (LRU) 알고리즘
LRU 알고리즘의 핵심 아이디어는 간단하다. 캐시가 가득 찼을 때, 가장 오랫동안 사용하지 않은 데이터를 제거하는 것이다. 이 알고리즘은 "시간적 지역성(Temporal Locality)"이라는 원리에 기반한다. 즉, 최근에 사용한 데이터는 가까운 미래에 다시 사용될 가능성이 높다는 가정이다.

위 그림은 캐시 크기가 3일 때 LRU 알고리즘이 어떻게 동작하는지 보여준다. 페이지 7, 0, 1, 2를 순서대로 참조하면 캐시가 채워진다. 이후 페이지 0을 다시 참조하면 이미 캐시에 있으므로 히트(Hit)가 발생한다. 하지만 새로운 페이지 3을 참조할 때 캐시가 가득 차 있다면, 가장 오래전에 사용된 페이지 7이 제거되고 페이지 3이 그 자리를 차지한다. OS 시험 빈출 유형이니 처음 봤다면 연습해보자ㅎㅎ
2.3 LRU는 항상 효율적일까?
LRU 알고리즘이 항상 최선의 선택은 아니다. 작업 대상의 특성에 따라 효율성이 크게 달라진다.
이를 확인하기 위해 세 가지 대표적인 시나리오에서 실험을 진행해보자.
실험 설계
비교 대상 알고리즘
- OPT (Optimal): 미래에 어떤 페이지가 참조될지 미리 안다고 가정하는 이론적 최적 알고리즘. 실제로는 구현 불가능하지만 다른 알고리즘의 성능을 평가하는 기준점이 된다.
- LRU (Least Recently Used): 가장 오래 사용하지 않은 페이지를 제거한다.
- FIFO (First In First Out): 먼저 들어온 페이지를 먼저 제거. 최근 사용 여부를 고려하지 않는다.
- RAND (Random): 무작위로 페이지를 제거한다.
실험 방법
- 총 100건의 페이지 접근이 발생한다고 가정한다.
- 캐시 크기를 점진적으로 늘려가며 각 알고리즘의 히트율 변화를 관찰한다.
-> 히트율이 높을수록 캐시에서 데이터를 찾는 비율이 높아 성능이 좋다는 의미다.
이제 세 가지 워크로드 패턴에서 각 알고리즘이 어떻게 동작하는지 살펴보자.
1) No-Locality Workload : 랜덤 접근
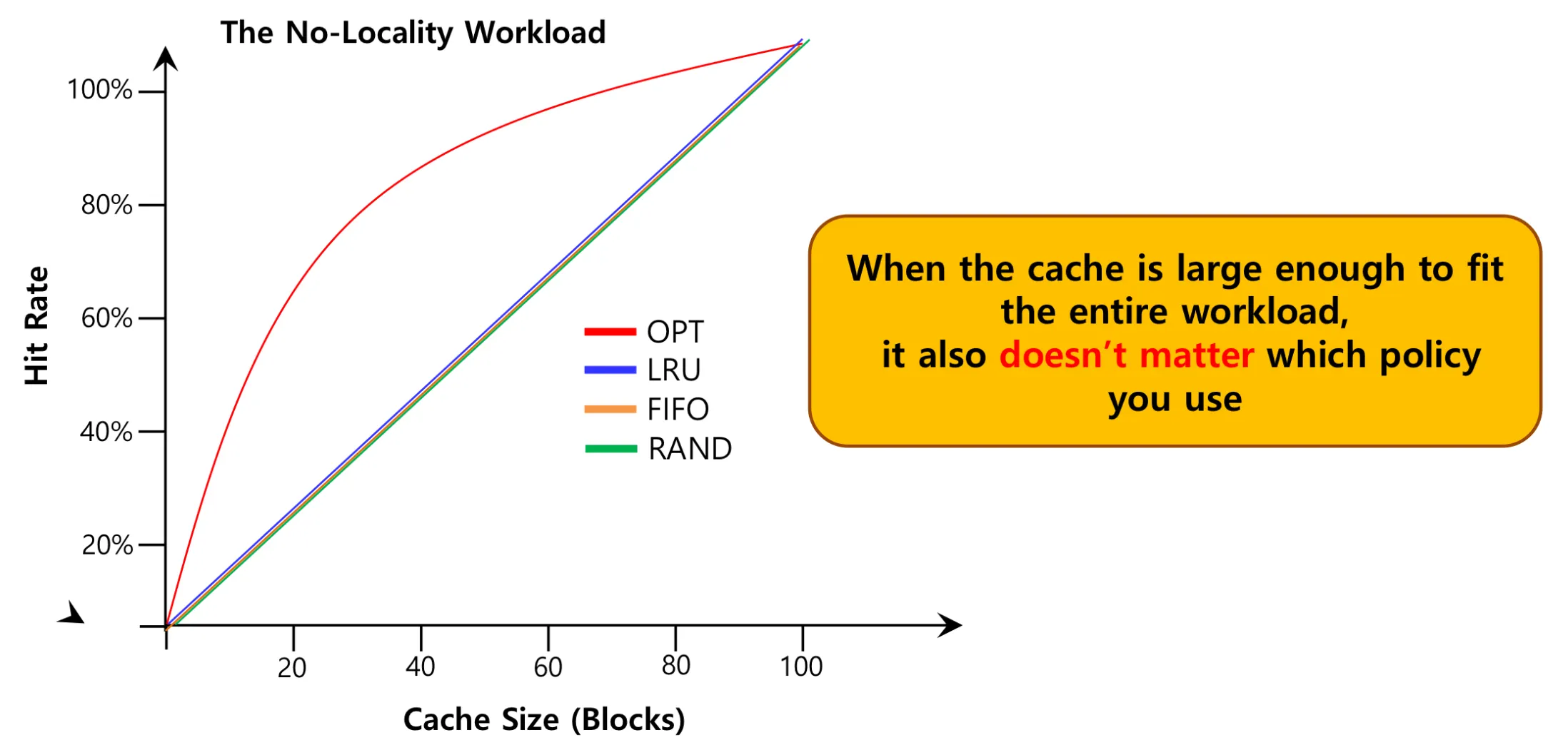
첫 번째는 완전히 랜덤하게 페이지를 참조하는 경우다.
이런 상황에서는 "최근에 사용한 것을 다시 사용할 가능성이 높다"는 LRU의 가정이 성립하지 않는다. 즉, 시간적 지역성이 완전히 무시된다. 그래프를 보면 LRU, FIFO, RAND 등 어떤 알고리즘을 사용하든 히트율에 큰 차이가 없다. 캐시 크기를 늘려도 히트율이 선형적으로만 증가할 뿐이다.
실제로 이런 워크로드는 드물지만, 페이지 접근 패턴에 규칙성이 전혀 없다면 LRU의 이점이 사라진다는 것을 보여준다.
2) 80-20 Workload: Locality를 고려한 접근

전체 참조의 80%가 오직 20%의 페이지에 집중되는 실험이다. (파레토 법칙)
이런 상황에서 LRU는 빛을 발한다. 그래프를 보면 LRU가 FIFO나 RAND보다 훨씬 높은 히트율을 보인다. 자주 사용되는 "핫" 페이지들을 LRU가 효과적으로 캐시에 유지하기 때문이다.
실제 데이터베이스 환경은 대부분 이런 패턴을 보인다. 최신 게시글, 인기 상품, 자주 조회되는 사용자 정보 등 특정 데이터에 접근이 집중되기 때문이다.
3) The Looping Sequential: LRU의 약점 🚨

100개의 페이지에 접근할 때, 0번 부터 49번 페이지까지 순차적으로 2번의 루프를 돌며 접근하는 실험이다.
캐시 사이즈가 49개인 상황에서 LRU 알고리즘을 가정해보자. 처음에 페이지 0~48을 읽으면 캐시가 거의 가득 찬다. 이제 페이지 49를 읽으려고 하면 가장 오래된 페이지 0이 제거된다. 다시 루프가 시작되어 페이지 0을 읽으려고 하면? 이미 제거되었으므로 캐시 미스가 발생한다. 이런 식으로 계속 미스가 반복되어, 캐시 사이즈가 50개 미만일 때는 0%의 히트율이 기록된다. 캐시 크기가 50을 넘어가는 순간 모든 페이지를 담을 수 있게 되면 히트율이 100%로 수직 상승한다.
이러한 Looping Sequential한 작업에서는, RAND가 LRU나 FIFO보다 더 나은 성능을 보인다.
데이터베이스 예시
- Full Table Scan: 테이블 전체를 순차적으로 읽는 경우
- Batch 작업: 대량의 데이터를 한 번에 처리하는 경우
- 백업이나 통계 작업: 모든 데이터를 한 번씩 훑는 경우
예를 들어 이런 쿼리를 실행한다면
-- WHERE 조건 없이 전체 테이블 조회
SELECT * FROM articles;
이 쿼리 하나가 100만 개의 페이지를 순차적으로 읽으면서 버퍼 풀에 있던 자주 쓰는 데이터를 모두 밀어낼 수 있다. (뒤에 설명하겠지만, InnoDB 기준 실제로는 밀려나지 않는다.)
그 결과 이후에 실행되는 일반 쿼리들이 갑자기 느려지는 현상이 발생할 수 있다.
이것이 바로 InnoDB가 단순한 LRU를 사용하지 않고 개선된 버전을 사용하는 이유다. 다음 섹션에서 InnoDB의 해결책을 살펴보자.
2.4 InnoDB의 LRU 전략
전통적인 LRU의 문제를 해결하기 위해, InnoDB는 Midpoint Insertion Strategy라는 개선된 방법을 사용한다. 핵심 아이디어는 간단하다. LRU 리스트를 두 영역으로 나누고, 새로 읽은 페이지를 바로 "가장 최근 사용" 위치에 넣지 않는 것이다.
LRU 리스트의 구조
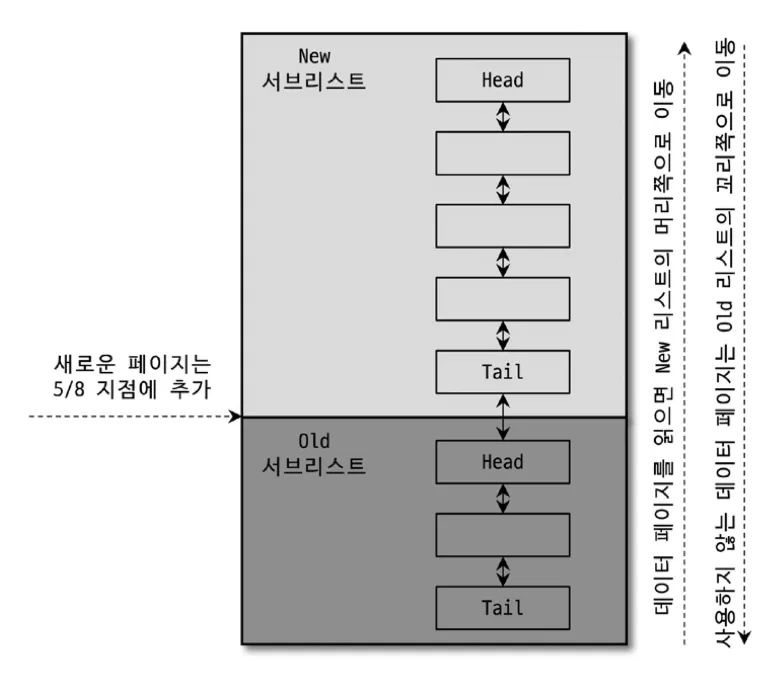
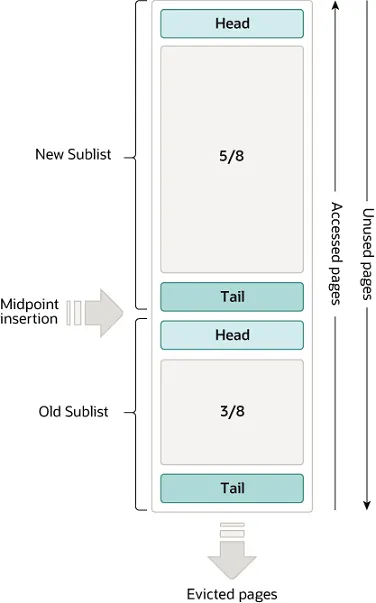
InnoDB 버퍼 풀의 LRU 리스트는 New Sublist와 Old Sublist로 나뉘어 관리된다:
두 리스트가 만나는 지점을 Midpoint라고 부르며, 새로 읽은 페이지는 바로 여기에 삽입된다.
동작 방식
InnoDB의 개선된 LRU는 다음과 같이 작동한다.
- 처음 읽을 때 - Midpoint에 삽입
디스크에서 새로운 페이지를 읽으면 Old Sublist의 Head에 삽입한다.
전통적인 LRU처럼 바로 리스트의 최상단(New의 Head)에 넣지 않는다. - 재접근 시 - 시간 검증 후 승격
Old 영역에 있는 페이지를 다시 접근할 경우 두 가지 동작이 가능하다:
1) 1초 이내 재접근: 그대로 유지 (일회성 스캔으로 간주)
2) 1초 이후 재접근: New Sublist의 Head로 승격 (진짜 필요한 데이터로 인정)
이 1초라는 시간 기준은 innodb_old_blocks_time 설정값이다 (기본 1000ms). - 미사용 시 - 점진적 이동
오랫동안 접근하지 않은 페이지는 점점 리스트의 Tail 쪽으로 밀려난다.
New 영역에 있던 페이지도 사용하지 않으면 결국 Old 영역으로 내려가고, 최종적으로는 Old의 Tail에서 퇴출된다. - 퇴출
버퍼 풀이 가득 차고 새로운 페이지가 필요하면, Old Sublist의 Tail에 있던 페이지가 제거된다. New 영역의 페이지는 보호받는다.
왜 효과적인가?
LRU 리스트를 Old와 New 두개로 나눠서 관리하는 전략은, 위에서 봤던 Looping Sequential 문제를 개선할 수 있다.
- Full Scan 실행
- 100만 개 페이지가 Old의 Head(Midpoint)에 삽입됨
- 이 페이지들은 Old 영역(3/8)만 순환하며 빠르게 퇴출됨, New 영역(5/8)의 핫 데이터는 전혀 건드리지 않음
- 이후 일반 쿼리 실행
- 필요한 페이지가 여전히 New 영역에 있음! → 메모리에서 빠르게 응답
InnoDB의 LRU 리스트는 자주 쓰는 데이터와 한 번만 쓰는 데이터를 구분한다. 덕분에 일회성 대량 조회가 있어도 핵심 데이터는 보호받고, 우리가 경험한 것처럼 반복 조회 시 안정적으로 빠른 성능을 유지할 수 있다.
3. 실전에서는 어떻게?
이제 InnoDB Buffer Pool이 무엇이고, 어떻게 동작하며, 왜 이것이 MySQL시 매우 중요한 요소 중 하나인지 깨달았다.
그럼 실전에서는 어떻게 버퍼풀을 최대로 활용할 수 있을까?
3.1 버퍼 풀 크기 설정하기
기본 설정의 문제
MySQL의 기본 버퍼 풀 크기는 128MB다. 이상적으로는 버퍼 풀을 가능한 한 크게 설정하는 것이 좋다. 버퍼 풀이 클수록 더 많은 데이터를 메모리에 유지할 수 있고, InnoDB는 마치 인메모리 데이터베이스처럼 동작할 수 있다.
권장 크기 가이드
서버의 물리 메모리에 따른 권장 설정은 다음과 같다 (Real MySQL 기준):
| 서버 메모리 | 권장 버퍼 풀 크기 |
| < 8GB | 50% |
| 8GB ~ 50GB | 50% → 점진적 증가로 최적 값 찾기 |
| ≥ 50GB | 전체 - (15~30GB) |
설정 방법
my.cnf 파일에 다음과 같이 설정한다:
[mysqld]
# 서버 메모리 16GB 기준 예시
innodb_buffer_pool_size = 12G설정 후 MySQL을 재시작하면 적용된다.
3.2 Cold Start 대응하기
문제 상황
서버를 재시작하면 버퍼 풀이 비워진다. 이후 처음 접속하는 사용자들은 모든 데이터를 디스크에서 읽어야 하므로 느린 경험을 하게 된다. 특히 서비스 재배포나 장애 복구 직후에는 일시적으로 전체 응답 속도가 느려질 수 있다.
어떻게 대응할 수 있을까?
방법 1: Warming Up
애플리케이션 시작 시 주요 쿼리를 미리 실행하여 버퍼 풀을 워밍업 시킨다.
@Component
public class BufferPoolWarmer implements ApplicationRunner {
private final ArticleRepository articleRepository;
@Override
public void run(ApplicationArguments args) {
log.info("버퍼 풀 워밍업 시작");
// 자주 조회되는 최신 게시글 미리 로드
articleRepository.findTop1000ByOrderByCreatedAtDesc();
// 인기 게시글 미리 로드
articleRepository.findByClicksGreaterThanOrderByClicksDesc(1000);
log.info("버퍼 풀 워밍업 완료");
}
}방법 2: 버퍼 풀 복구 (자동화)
MySQL의 자동 복구 기능을 활성화하면, 종료 시 버퍼 풀 상태를 저장했다가 재시작 시 자동으로 복구한다.
my.cnf에 다음 두 줄만 추가하면 된다:
[mysqld]
# 종료 시 버퍼 풀 상태 저장
innodb_buffer_pool_dump_at_shutdown = 1
# 시작 시 버퍼 풀 상태 복구
innodb_buffer_pool_load_at_startup = 1동작 방식:
- MySQL 종료 시: 버퍼 풀의 페이지 정보를 파일(ib_buffer_pool)에 저장
- MySQL 시작 시: 저장된 페이지들을 디스크에서 다시 읽어 버퍼 풀에 적재
3.3 질문으로 돌아가서
이제 처음에 던졌던 질문들에 답할 수 있다.
- 최초 조회만 유독 시간이 오래 걸리는 정확한 이유는 무엇일까❓
→ 데이터가 디스크에 있어서. 버퍼 풀에 적재되는 시간이 필요하다. 디스크는 메모리보다 수천~수만배 느리다. - 이것은 문제 상황일까, 아니면 정상 동작일까❓
→ 정상 동작이다. 모든 데이터를 메모리에 올릴 수 없으므로 피할 수 없다. 하지만 적절한 대응은 필요하다. - 최초 조회 결과도 성능 측정에 포함시켜야 할까❓
→ 측정 목적에 따라 다르다. 정상 운영 중 성능을 확인하려면 제외하고 워밍업 후 측정. - 실제 서비스에서 첫 사용자가 느린 경험을 하는 건 괜찮을까❓
→ 괜찮지 않다. 버퍼 풀 크기 최적화 + 자동 복구 설정 + Warming Up으로 대응해야 한다.
"쿼리가 느리다"는 단순한 현상 뒤에는 디스크와 메모리의 근본적인 속도 차이, 제한된 자원을 관리하는 LRU 알고리즘, 실제 워크로드를 고려한 InnoDB의 Midpoint Insertion까지 여러 계층의 지식이 얽혀있었다.
이제 우리는 이 현상을 정확히 이해하고, 실전에서 적절히 대응할 수 있다.
참고 자료
- MySQL 공식 문서 - InnoDB Buffer Pool
- Real MySQL 8.0 (백은빈, 이성욱 저) - 04. 아키텍처
- Operating Systems: Three Easy Pieces - 22. Beyond Physical Memory: Policies